Gen AI Intensive Course Capstone 2025Q1
This is the blog for Gen AI Intensive Course Capstone 2025Q1 Project which is part of 5-Day Gen AI Intensive Course with Google

Project Title: ⚡Watt-Saver – The Personalized Energy Coach
💡 Understanding Energy Bills with GenAI:
Many people receive energy bills without knowing why they’re high or how to reduce them. This project shows how Generative AI (GenAI) can help users understand their energy consumption and get personalized, human-readable feedback.
❓ Why/How GenAI can solve the problem?
Charts and numbers alone don’t help most people take action. GenAI transforms raw energy data into insightful narratives—like identifying your most expensive usage days and suggesting practical changes in behavior or device usage.
🔍 How It Works
We used hourly energy consumption data from a single home. After cleaning and summarizing it, we prompted Gemini (a GenAI model) to explain trends—like why usage spiked on certain days—and offer tips to reduce costs.
📊 Key Results
Instead of just visualizing data, Gemini responded with plain-language insights and personalized advice. It helped reveal things like:
- Which time of day is most expensive
- When heating/cooling is overused
- How to shift usage to off-peak hours
🚀 Impact
This approach can scale to households or communities. Tools like Watt-Saver using GenAI to suggest smarter energy use—helping people cut costs and reduce waste without needing technical skills.
👥 Team Members and Roles
- Jim - Lead code, blog developer and project submitter
- Lamide - Few short prompt developer, Youtube video producer
- Saad Asghar - GenAI capability tester
- Jgar1597 - LongGraph agent developer, Youtube video producer
🧠 Advisers
💻 Notebook Link
💾 Dataset
🎥 Youtube Video
Why it is useful and people should care about❓
💭 Most people are unaware of exactly how and where their energy is being consumed and what it truly costs 💸. Energy usage varies widely based on factors like house size, weather and seasonal changes (hot or cold), and personal habits — such as watching TV at night, charging an EV at midnight, or using a PC during the day. These overlapping variables make it difficult for a person to identify patterns or optimize energy use🧾.
As a working professional who works from home, I spend a lot of time on my PC throughout the day. In the evenings, I often unwind by watching Netflix, and I regularly cook my own meals. These habits are pretty consistent, yet sometimes I receive unexpectedly high energy bills — and it’s not always clear why 🤔.
Despite being mindful of my usage, it’s difficult to pinpoint exactly where the spikes are coming from or how I can optimize my consumption without compromising comfort or routine.
💡 However, with the power of Generative AI, it’s possible to uncover hidden patterns within this data and provide smart, efficient recommendations for reducing energy waste and improving usage 🚀.
📉 What was achieved from this project and the result:
-
Analyzed two datasets by leveraging
document and image understandingcapabilities. -
Utilized GenAI
prompt engineeringto construct complex SQL queries inJSONformat, group similar data, and store it in a database. -
Employed
function callingto query the database while interacting with Gemini to ask questions about the energy data. -
Identified the highest and lowest energy consumption and costs based on specific time periods, such as from 6 AM to 12 PM.
-
Built a
Neural Networkand appliedgradient descentandlinear regressionto predict future energy consumption and costs using real-time weather data. The model was saved into a database. -
Developed a GenAI agent using
LongGraph. The agent could query the database viafunction callingusing LongGraph’s@tooldecorator to retrieve specific data and make predictions. The agent then responded like a personal “energy coach” providing insights into energy usage, costs, and optimization strategies to reduce both, based on the analyzed energy data.
🔍 The following are screenshots of brief summary of the insights and recommendations generated by Gemini and the AI agent:
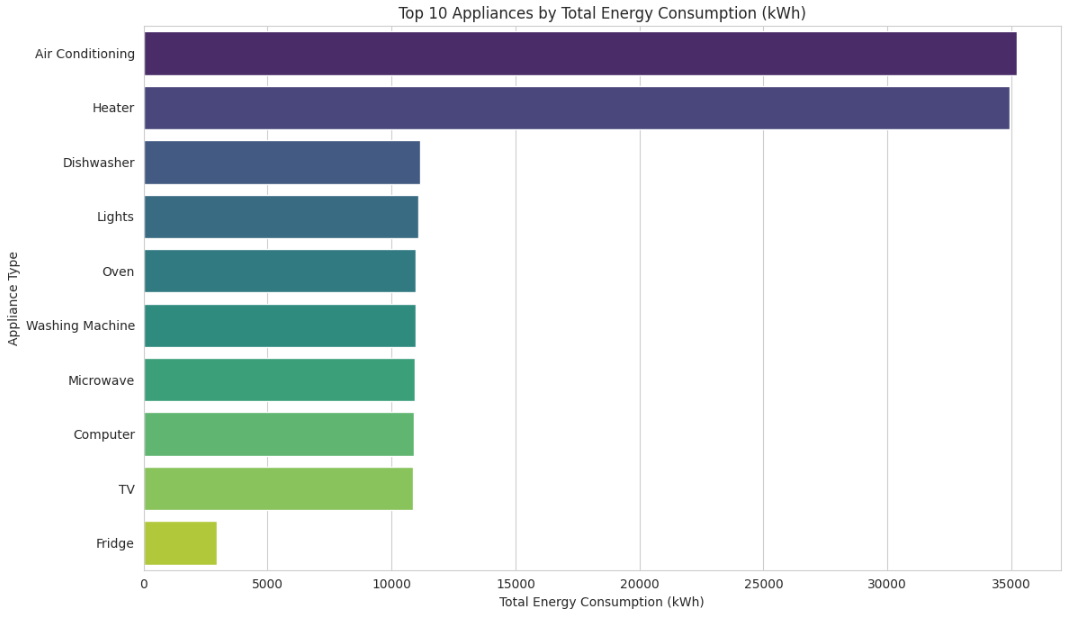
- Utilized Gemini to analyze the data, highlighting the highest energy consumption:
- Compared the highest and lowest energy consumption by analyzing
Appliance type,household size,season,outdoor temperatureandtime block: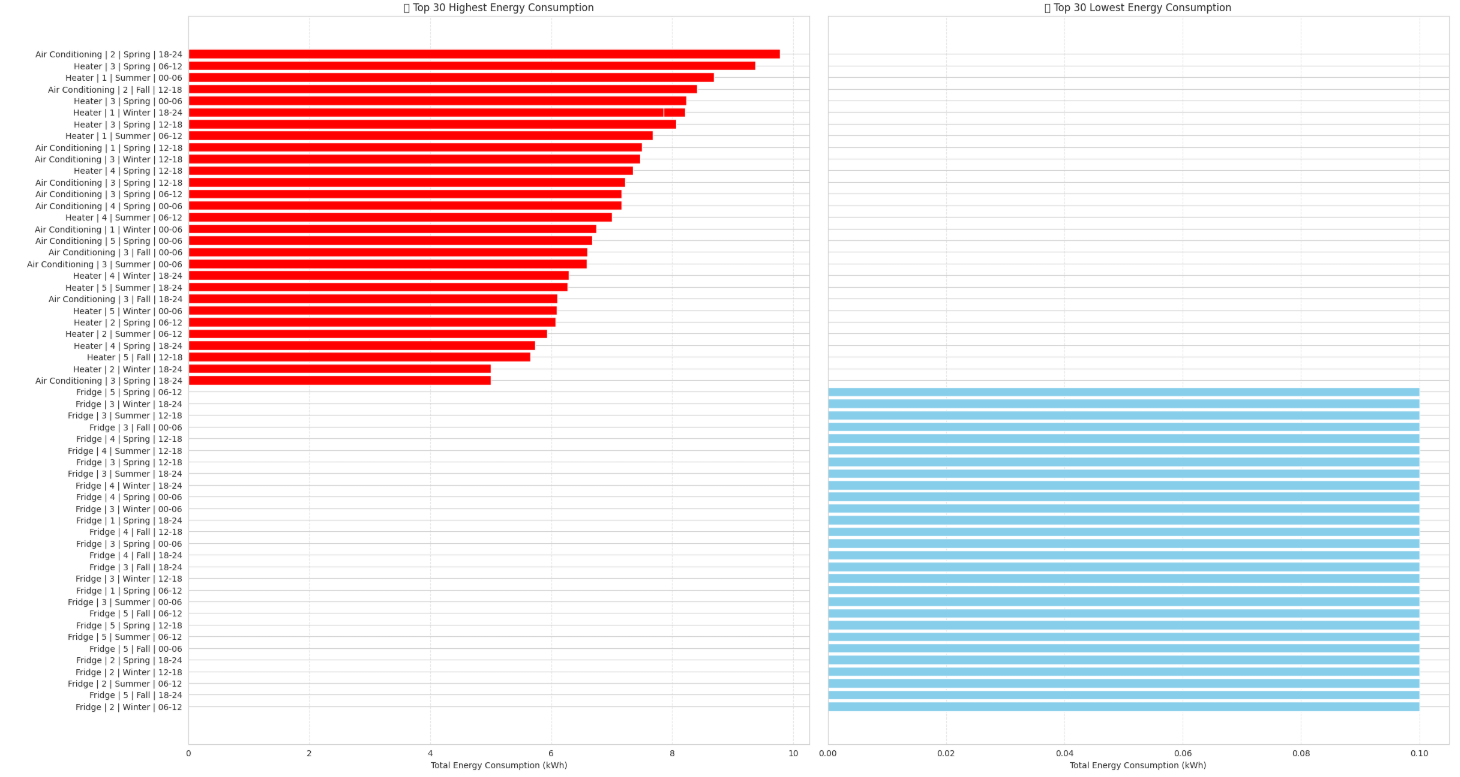
- Asked the model for key insights and actionable suggestions:

- Trained a model to predict energy consumption and costs by supplying real-time weather data:

- Built an AI chat agent using the analyzed data and the trained model, with everything stored in the database:


🛠️ Detailed Code Snippets to Demonstrate How It Was Implemented
We start of by loading the two datasets
/kaggle/input/energy-data-meter-2/energy_hourly_data_2024_meter2.dat
/kaggle/input/smart-home-energy-consumption/smart_home_energy_consumption_large.csv
We will use pd.read_csv to display both datasets and get a overview of them:
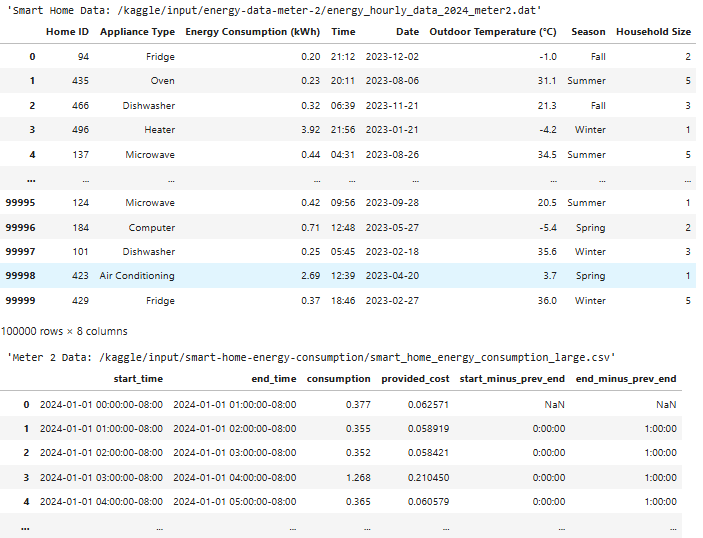
The data can be a bit challenging to interpret at a glance, so we’ll use Generative AI to help make sense of it. Specifically, we’ll leverage the Document Understanding capabilities from Day2’s colab, along with the Image Understanding features demonstrated in the Bonus Day’s notebook.
Apply Document understanding to describe the datasets
Use client.models.generate_content to read the datasets and we set teamperature 0.0 to make the output consistant.
from kaggle_secrets import UserSecretsClient
request = """
I have two datasets related to household energy usage.
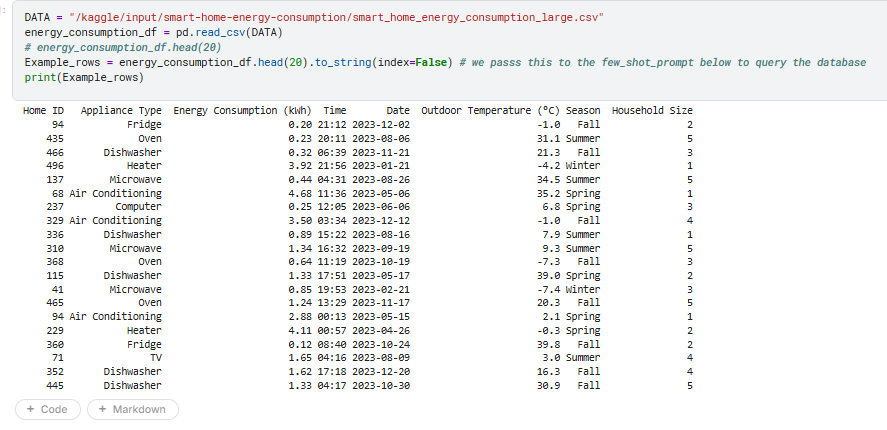
Dataset 1 (`document_file1`) contains detailed energy usage events per appliance. It includes:
- Home ID
- Appliance Type
- Energy Consumption (kWh)
- Time
- Date
- Outdoor Temperature (°C)
- Season
- Household Size
Dataset 2 (`document_file2`) is an hourly energy consumption log. It includes:
- start_time and end_time
- Total consumption and calculated cost
- Time gap from previous record
Please help me:
1. Understand what each dataset represents individually.
2. Identify the relationship between them (e.g., how appliance-level data aggregates into the hourly logs).
3. Summarize key insights:
- Typical daily usage and cost trends
- Any notable peaks, anomalies, or patterns across seasons, time blocks, or appliances
- Suggestions for reducing energy waste or optimizing efficiency
- The fixed rate per kWh appears to be in `provided_cost`—please estimate and confirm it
4. Guide me with Python code snippets to:
- Preprocess and clean each dataset
- Group and compare hourly vs appliance-based usage
- Identify high-usage appliances or inefficient patterns
- Suggest energy-saving opportunities from the data
"""
def summarise_doc(request: str) -> str:
"""Execute the request on the uploaded document."""
# Set the temperature low to stabilise the output.
config = types.GenerateContentConfig(temperature=0.0)
response = client.models.generate_content(
model='gemini-2.5-pro-exp-03-25',
config=config,
contents=[request, document_file1,document_file2], # Analyze thetotal 2 dataset (documents) here
)
return response.text
summary = summarise_doc(request)
Markdown(summary)
look at the following output, we can the the Gemini gave the overview of the datasets and some code snippets for analyzing them.
 ✅ The model gave a very quick overview of the datasets and how should we analysis them by providing code snippets:
✅ The model gave a very quick overview of the datasets and how should we analysis them by providing code snippets:
🤖 What the code does:
- Load Data: Reads both CSV and DAT files using pandas. Includes basic error handling for file loading.
- Preprocessing Dataset 1 and Dataset 2
- Estimate Cost per kWh: Calculates the cost per kWh from Dataset 2 (provided_cost / total_consumption). It uses the median for robustness and shows statistics/histogram to check if the rate is consistent (fixed).
- Compare Hourly vs. Appliance Data:
- Plots the comparison for a sample period.
- Identify High-Usage Appliances & Patterns:
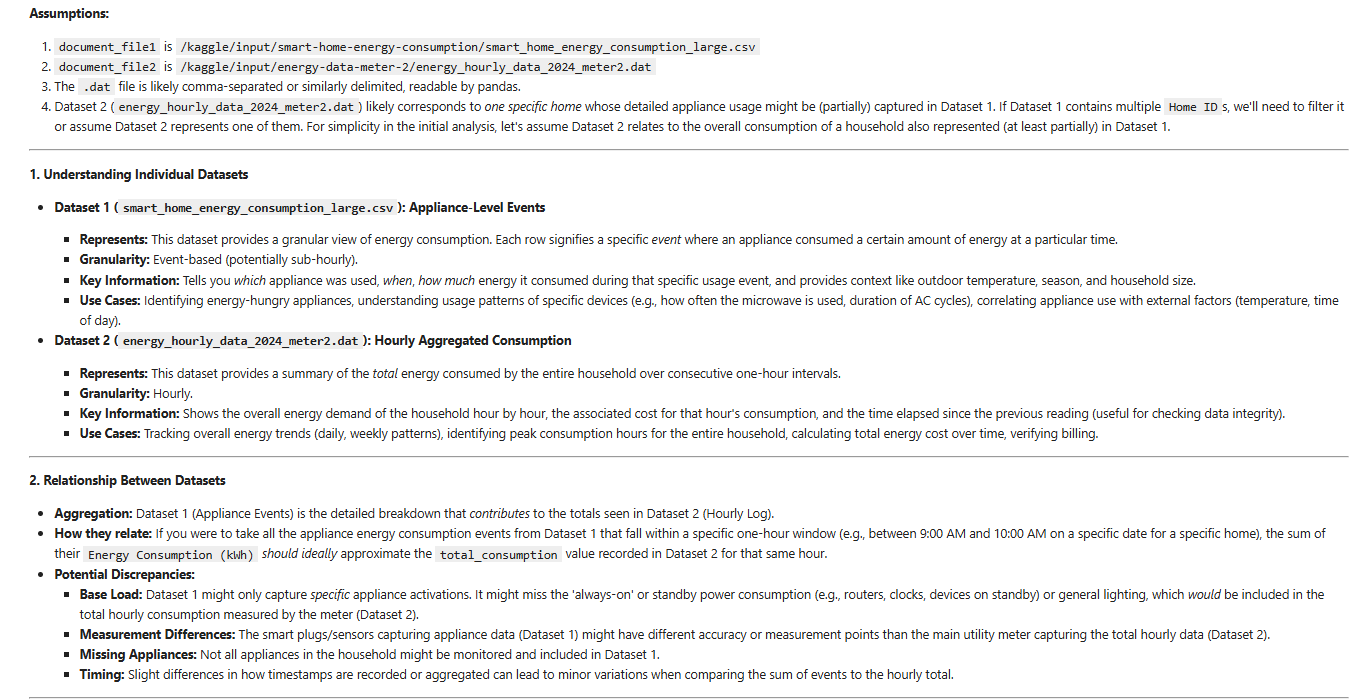
We can see the plot to have an quick grasp of the data and see Air conditioning and Heater have the highest energy consumption during the time period.
and outdoor tempture vs consumption
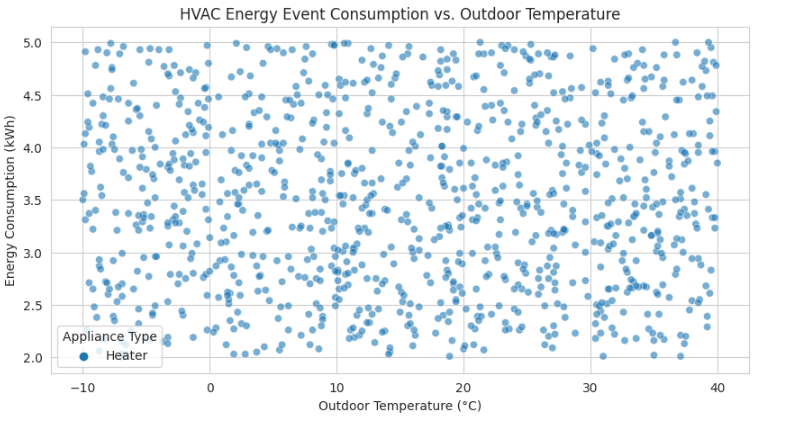
The second dataset is more meter data of a single household for one year on hourly basis and the other one is appliances of 500 households over multiple time period
We will analysis this energy_hourly_data_2024_meter2.dat dataset to get the fixed rate, daily consumption and top 10 days useage
# Load with tab separator and column names
df = pd.read_csv(
"/kaggle/input/energy-data-meter-2/energy_hourly_data_2024_meter2.dat",
sep="\t",
names=["start_time", "end_time", "consumption", "provided_cost",
"start_minus_prev_end", "end_minus_prev_end"],
header=None,
on_bad_lines='skip'
)
...
print(daily_data.head())
We can see the daily consumption and the cost
| start_time | consumption | provided_cost |
|---|---|---|
| 2024-01-01 00:00:00+00:00 | 22.064 | 3.66196 |
| 2024-01-02 00:00:00+00:00 | 70.308 | 11.669 |
| 2024-01-03 00:00:00+00:00 | 53.101 | 8.81317 |
| 2024-01-04 00:00:00+00:00 | 51.451 | 8.53932 |
| 2024-01-05 00:00:00+00:00 | 57.207 | 9.49465 |
📊 Visualizing Daily Energy Consumption and Cost
This section uses matplotlib to create a dual-axis line chart that visualizes daily energy consumption (kWh) and cost ($) on the same plot, but with separate Y-axes for clarity.
This uses a twin axis plot so you can display both energy consumption and cost over time without overcrowding one axis. fig.autofmt_xdate() automatically rotates the X-axis date labels to prevent overlap.
The combined legend includes both data series, making the chart easy to interpret.
import matplotlib.pyplot as plt
fig, ax1 = plt.subplots(figsize=(14, 6))
# Plot daily energy consumption
color1 = 'tab:blue'
ax1.set_xlabel("Date")
ax1.set_ylabel("Consumption (kWh)", color=color1)
ax1.plot(daily_data.index, daily_data['consumption'], label='Consumption (kWh)', color=color1, linewidth=2)
ax1.tick_params(axis='y', labelcolor=color1)
# Second y-axis for cost
ax2 = ax1.twinx()
color2 = 'tab:purple'
ax2.set_ylabel("Cost ($)", color=color2)
ax2.plot(daily_data.index, daily_data['provided_cost'], label='Cost ($)', color=color2, linestyle='dashed', linewidth=2)
ax2.tick_params(axis='y', labelcolor=color2)
# Grid, legend, title
fig.suptitle("Daily Energy Consumption & Cost (Resampled from Hourly)", fontsize=16)
...
# Combined legend from both axes
lines, labels = ax1.get_legend_handles_labels()
...
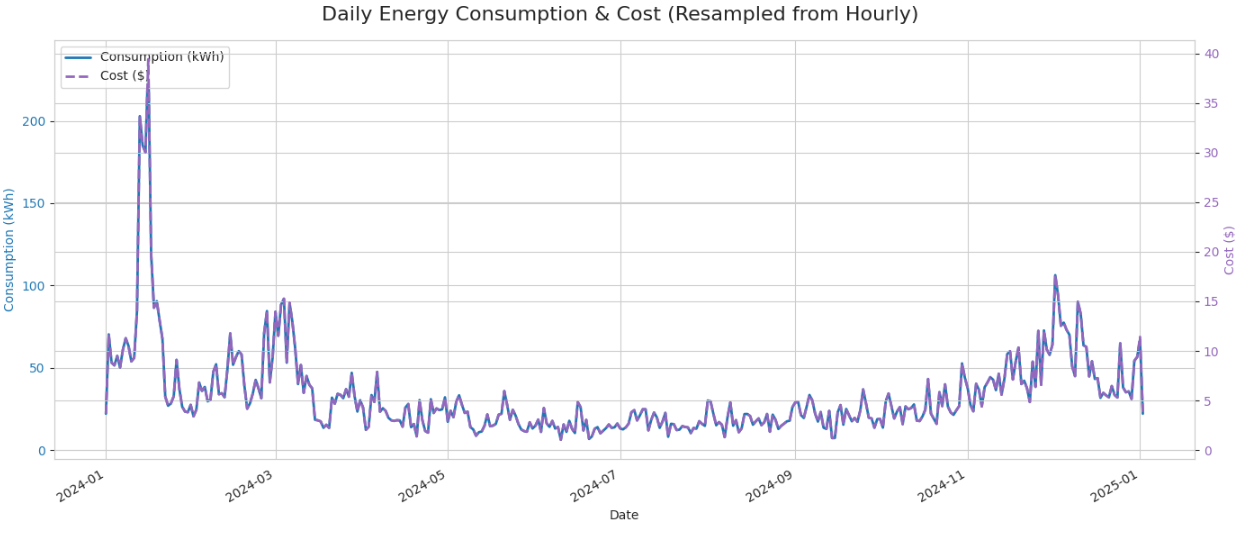
📌We can see there is a energy spike around 2024-01, and we need to figure out the reason that caused energy spike
Applying Image Understanding
import PIL
prompt = [
"""
Please give me a friendly explanation of what this image shows in a couple of paragraphs
Please summarize key insights, including:
- Typical daily usage and cost
- Any significant variations or outliers such as around 2024-01 it has a consumption spike, find out the reasons might be
- Suggestions to reduce energy waste or improve efficiency (even if rate is fixed)
- whats the fixed-rate of per kWh?
""",
PIL.Image.open("/kaggle/working/daily_energy_consumption.png"),
]
response = client.models.generate_content(
model='gemini-2.0-flash',
contents=prompt
)
Markdown(response.text)

It had some guesses of the spike we will use Retrieval Augumented Generation(RAG) with Gemini for generating Summary and Insights and image generation capability
summary_stats = daily_data.describe().round(2).to_string()
prompt = f"""
You are a skilled Energy Analyst. You will help with a variety of tasks related to Energy Usage.
Please:
- Generate a 3D-style rendered image that visually represents this data (e.g., 3D bar or surface plot).
- Include the x-axis as Date or Day, y-axis as Energy Consumption (kWh), and z-axis or color as Cost.
- Provide a brief written summary explaining key trends, variations, and what the household might improve.
The following table summarizes a household's daily energy usage (kWh) and daily cost (in $) over a fixed-rate plan:
{summary_stats}
Please summarize key insights, including:
- Typical daily usage and cost
- Any significant variations or outliers
- Suggestions to reduce energy waste or improve efficiency (even if rate is fixed)
- whats the fixed-rate of per kWh?
"""
response = client.models.generate_content(
model="gemini-2.0-flash-exp-image-generation",
contents=prompt,
config=types.GenerateContentConfig(
response_modalities=['text','image']
)
)
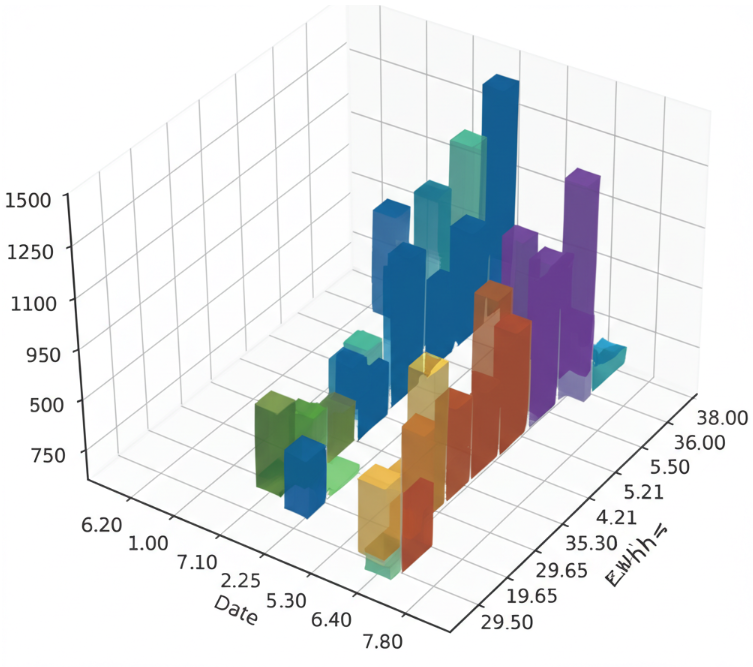
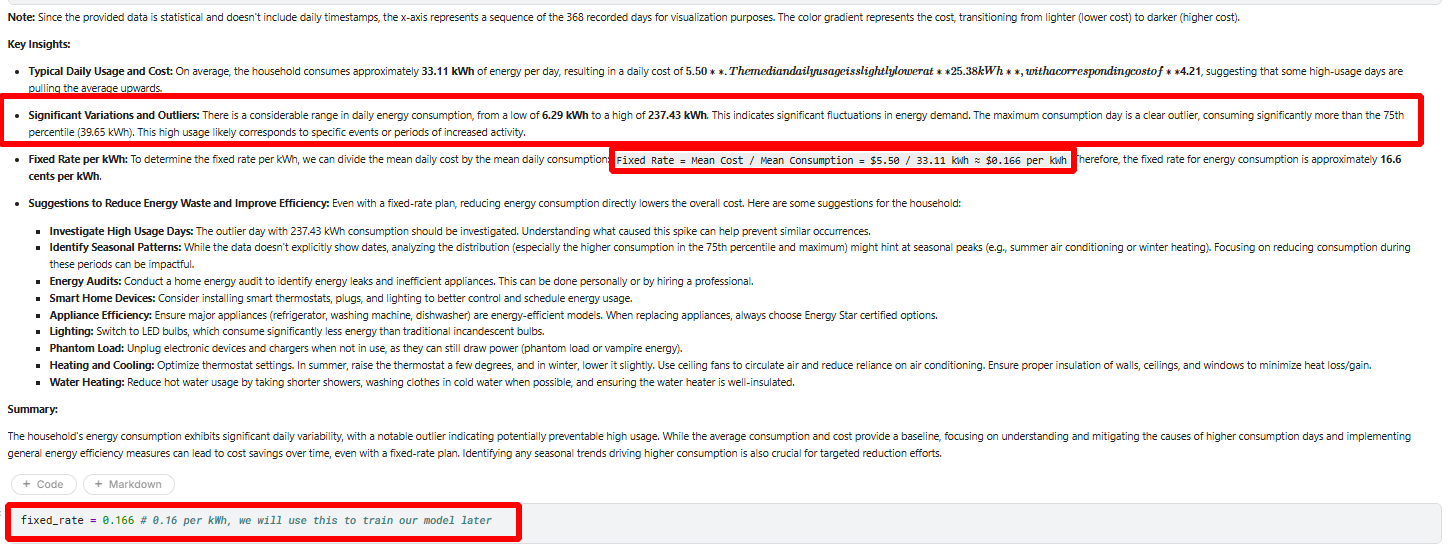
fixed_rate = 0.166 # 0.16 per kWh, we will use this to train our model later
The 3D image gave an overview of the enegery consumption and it text summrized the fixed rate,significant variations, and suggestions (Identifying any seasonal trends driving higher consumption is also crucial for targeted reduction efforts.). So let’s dig more by displaying summarized energy insight for the dataset
# we will create a matplotlib function
def display_energy_insight(
title: str,
insight_text: str,
df: pd.DataFrame = None,
df_caption: str = None,
plot_column: str = None,
plot_color: str = "skyblue"
):
.....
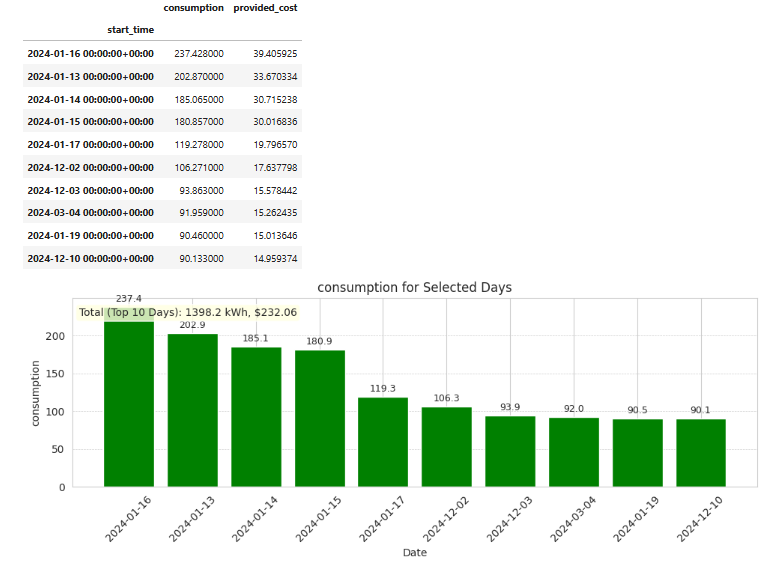
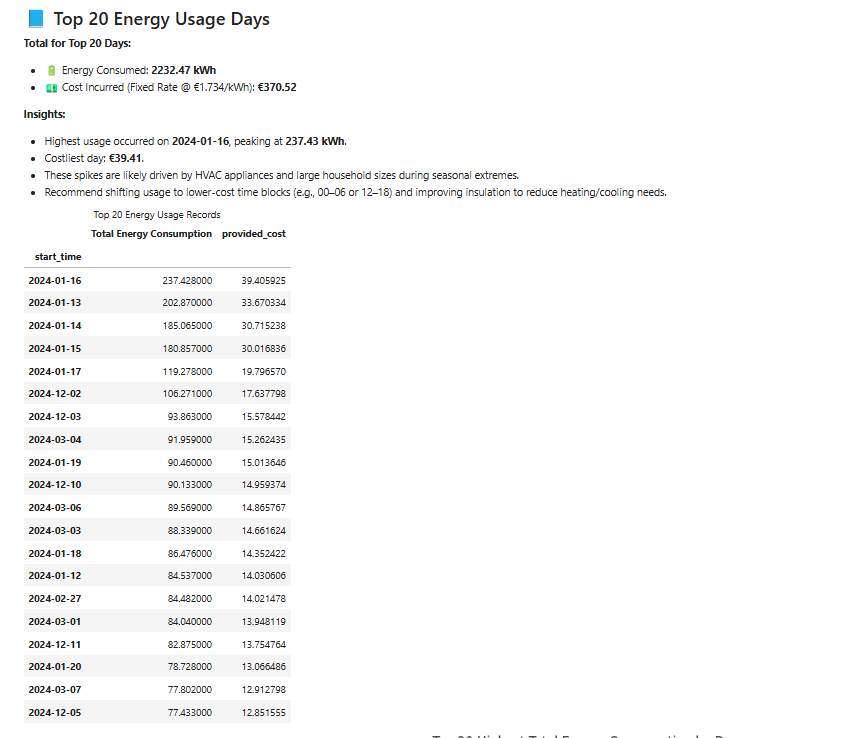
# then list top energy consumption days
top_days = daily_data.sort_values('consumption', ascending=False).head(5)
# Make a copy so we don't change the original
top_days_formatted = top_days.copy()
# Calculate sum of consumption and cost
total_kwh = top_days['consumption'].sum()
total_cost = top_days['provided_cost'].sum()
summary_text = f"""
**Total for Top 10 Days:**
- 🔋 Energy Consumed: **{total_kwh:.2f} kWh**
- 💵 Cost Incurred: **${total_cost:.2f}**
"""
We can clearly see the top 10 days consumption and costs
Utilize Database
We will analyze this dataset smart_home_energy_consumption_large.csv and will be considering the following factors that impacted the energy consumption from the dataset:
- Home ID
- Appliance Type
- Energy Consumption (kWh)
- Time
- Date
- Outdoor Temperature (°C)
- Season
- Household Size
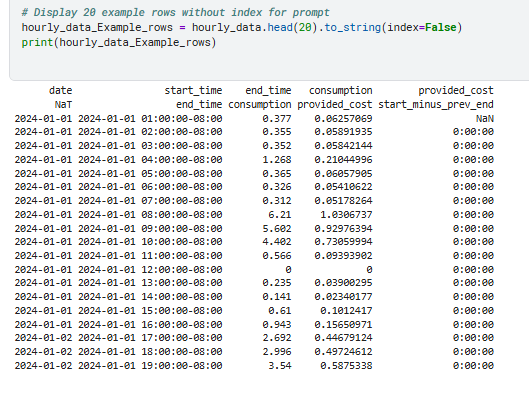
We save these two dateset in a database and created energy_data and hourly_data tables
conn = sqlite3.connect("mydatabase.db")
# Write the smart_home_energy_consumption_large.csv DataFrame to a SQL table named 'energy_data'
energy_consumption_df.to_sql("energy_data", conn,if_exists="replace", index=False)
# Write the energy_hourly_data_2024_meter2.dat DataFrame to a SQL table named 'hourly_data'
hourly_data.to_sql("hourly_data", conn,if_exists="replace", index=False)
# connect database
conn = sqlite3.connect("mydatabase.db",check_same_thread=False)
# connect to database
db = SQLDatabase.from_uri("sqlite:///mydatabase.db")
Markdown(db.get_table_info())
CREATE TABLE energy_data ( "Home ID" INTEGER, "Appliance Type" TEXT, "Energy Consumption (kWh)" REAL, "Time" TEXT, "Date" TEXT, "Outdoor Temperature (°C)" REAL, "Season" TEXT, "Household Size" INTEGER )
/* 3 rows from energy_data table: Home ID Appliance Type Energy Consumption (kWh) Time Date Outdoor Temperature (°C) Season Household Size 94 Fridge 0.2 21:12 2023-12-02 -1.0 Fall 2 435 Oven 0.23 20:11 2023-08-06 31.1 Summer 5 466 Dishwasher 0.32 06:39 2023-11-21 21.3 Fall 3 */
CREATE TABLE hourly_data ( date DATE, start_time TEXT, end_time TEXT, consumption TEXT, provided_cost TEXT )
/* 3 rows from hourly_data table: date start_time end_time consumption provided_cost None end_time consumption provided_cost start_minus_prev_end 2024-01-01 2024-01-01 01:00:00-08:00 0.377 0.06257069 None 2024-01-01 2024-01-01 02:00:00-08:00 0.355 0.05891935 0:00:00 */
Implement Shot prompt to generate SQL queries
We will implement shot prompt to generate SQL queries to get an overview of the database. First we define split 24 hours to 4 time blocks like below for a clear overview of energy consumption across a whole day
00:00–06:00 → 0-6
06:00–12:00 → 6-12
12:00–18:00 → 12-18
18:00–24:00 → 18-24
Then use define the JSON query to query SQL database regarding all the factors and group them
few_shot_prompt = f"""You are a SQL query generator. Parse natural language English questions into valid SQL query JSON for the `energy_data` table.
The `energy_data` table has the following schema:
- Home ID (INTEGER)
- Appliance Type (TEXT)
- Energy Consumption (kWh) (REAL)
- Time (TEXT, format 'HH:MM')
- Date (TEXT, format 'YYYY-MM-DD')
- Outdoor Temperature (°C) (REAL)
- Season (TEXT)
- Household Size (INTEGER)
Example rows:
{Example_rows}
Time blocks of the day are defined as:
- 00:00–06:00 → '00-06'
- 06:00–12:00 → '06-12'
- 12:00–18:00 → '12-18'
- 18:00–24:00 → '18-24'
Return your output in **valid JSON** format with the SQL query inside.
---
### EXAMPLE INPUT:
I want to find out the times with the highest and lowest energy consumption (kWh) in the energy_data table. Use ORDER BY and LIMIT to optimize the query.
For example, for 'Air Conditioning', what time blocks consume the most and least energy — like 6–12AM is highest and 12–6AM is the lowest? Always include a WHERE clause with: `Appliance Type` = ? when the question is appliance-specific.
---
### JSON Response:
```json
query
"""
Then the prompt would be:
ask_query = """
I want to find out what are the times with the highest and lowest Energy Consumption (kWh) in the energy_data table.
Use ORDER BY and LIMIT to optimize the query. Please filter by a specific appliance type and use Energy Consumption (kWh) AS Total_Energy_Consumption keyword.
add GROUP BY Time_Block, "date","Household Size", "Outdoor Temperature (°C)", "Season", "Appliance Type", without WHERE `Appliance Type`,
user defined schemas from the `energy_data` tables are Time_Block, "date","Household Size", "Outdoor Temperature (°C)", "Season", "Appliance Type"
"""
response = client.models.generate_content(
model='gemini-2.0-flash',
config=types.GenerateContentConfig(
temperature=0.1,
top_p=1,
max_output_tokens=500,
),
contents=[few_shot_prompt, ask_query])
We got the following SQL query printed as markdown format:

We got grouped output, that much easier to analyze the dataset
test_df = pd.read_sql_query(sql_query, conn)
display(combined_result)
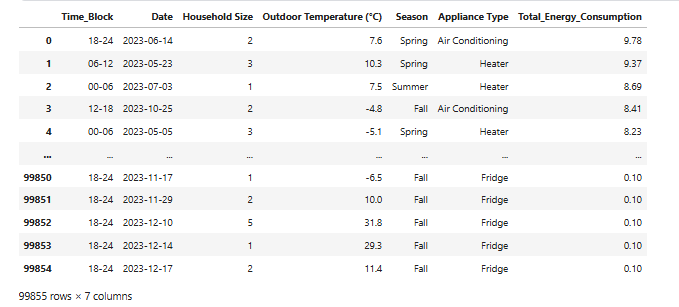
In order to further analyze it, we are storing it in database and creating a new table grouped_energy_data and hourly_data
combined_result.to_sql("grouped_energy_data", conn,if_exists="replace", index=False)
hourly_data.to_sql("hourly_data", conn,if_exists="replace", index=False)
db = SQLDatabase.from_uri("sqlite:///mydatabase.db")
Markdown
CREATE TABLE grouped_energy_data ( "Time_Block" TEXT, "Date" TEXT, "Household Size" INTEGER, "Outdoor Temperature (°C)" REAL, "Season" TEXT, "Appliance Type" TEXT, "Total_Energy_Consumption" REAL )
/* 3 rows from grouped_energy_data table: Time_Block Date Household Size Outdoor Temperature (°C) Season Appliance Type Total_Energy_Consumption 18-24 2023-06-14 2 7.6 Spring Air Conditioning 9.780000000000001 06-12 2023-05-23 3 10.3 Spring Heater 9.370000000000001 00-06 2023-07-03 1 7.5 Summer Heater 8.69 */
CREATE TABLE hourly_data ( date DATE, start_time TEXT, end_time TEXT, consumption TEXT, provided_cost TEXT )
/* 3 rows from hourly_data table: date start_time end_time consumption provided_cost None end_time consumption provided_cost start_minus_prev_end 2024-01-01 2024-01-01 01:00:00-08:00 0.377 0.06257069 None 2024-01-01 2024-01-01 02:00:00-08:00 0.355 0.05891935 0:00:00 */
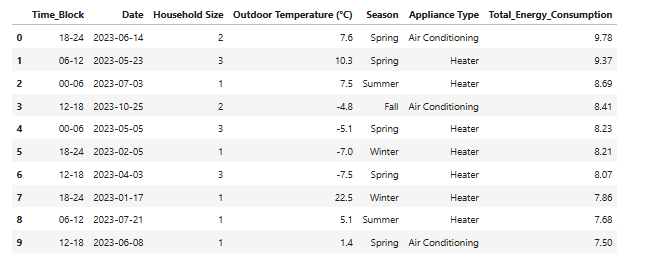
Lets try manually extracting highest enegry comsumption acrosss all the factors
highest = combined_result.loc[combined_result.groupby(['Appliance Type','Household Size',"Outdoor Temperature (°C)",'Season'])['Total_Energy_Consumption'].idxmax()]
highest_result = highest.sort_values(by='Total_Energy_Consumption',ascending=False)
# Reset index for a cleaner display
highest_result = highest_result.reset_index(drop=True)
display(highest_result.head(10))
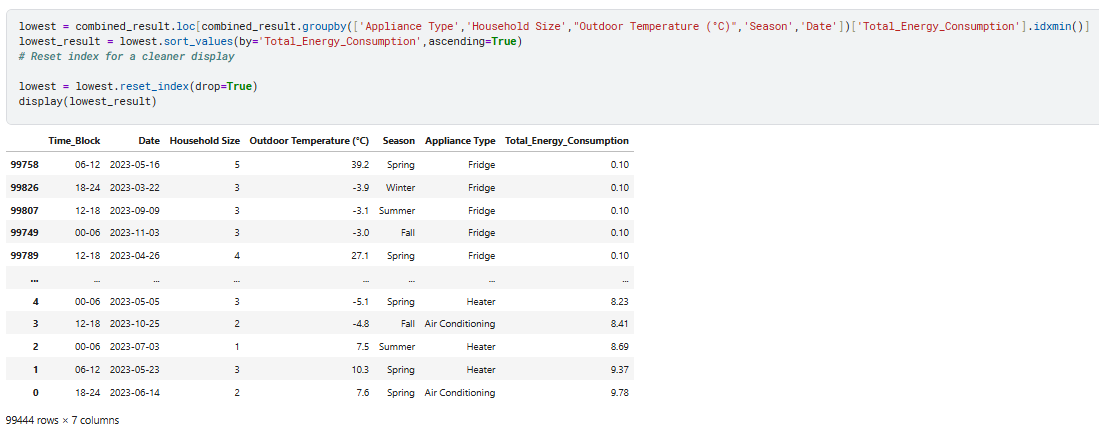
Same as for the lowest enegy consumption:
We created a simialr function to plot the data and compare highest and lowest enegy consumption for top 20 days
import matplotlib.pyplot as plt
from IPython.display import Markdown, display
# 🔧 Utility: Show energy insight as a bar chart
def display_energy_insight(
plt.tight_layout()
plt.savefig('/kaggle/working/top20_higest_result.png', dpi=300) # Save the plot
plt.show()
# 🔧 Utility: Compare highest vs lowest in two subplots
def compare_top_bottom_energy(highest_df, lowest_df):
# Ensure column naming consistency
high_plot = highest_df.head(30).copy()
low_plot = lowest_df.head(30).copy()
.....
# === PREPARE TOP-DAY BAR CHART for top 20 days ===
top_days = daily_data.sort_values('consumption', ascending=False).head(20)
top_days_formatted = top_days.copy()
....
- 🔋 Energy Consumed: **{total_kwh:.2f} kWh**
- 💵 Cost Incurred (Fixed Rate @ €{fixed_rate}/kWh): **€{total_cost:.2f}**
**Insights:**
- Highest usage occurred on **{top_days_formatted.index[0]}**, peaking at **{top_days_formatted.iloc[0]['Total Energy Consumption']:.2f} kWh**.
- Costliest day: **€{top_days.iloc[0]['provided_cost']:.2f}**.
- These spikes are likely driven by HVAC appliances and large household sizes during seasonal extremes.
- Recommend shifting usage to lower-cost time blocks (e.g., 00–06 or 12–18) and improving insulation to reduce heating/cooling needs.
"""
....
Form the results we can cleary see Aircondition 2 houre hold, between 18-24 in sprint has highest consumption Let ask GenAI to give some insights of the 2 compersing
from PIL import Image
# asking Gemni for both images, give summury
prompt = [
"""
Please give me a friendly explanation of what this image shows in a couple of paragraphs
Please summarize key insights, including:
- Typical daily usage and cost
- Any significant variations or outliers
- Suggestions to reduce energy waste or improve efficiency (even if rate is fixed)
""",
Image.open("/kaggle/working/higest_lowest_result.png"),
Image.open("/kaggle/working/top20_higest_result.png"),
]
response = client.models.generate_content(
model='gemini-2.0-flash',
contents=prompt
)
Markdown(response.text)

🤖 Train a model
The trained model would be able to predict likelihood energy consumption and costs on real weather and temperature data
Prepare dataset
combined_result.to_csv('/kaggle/working/combined_result.csv', index=False)
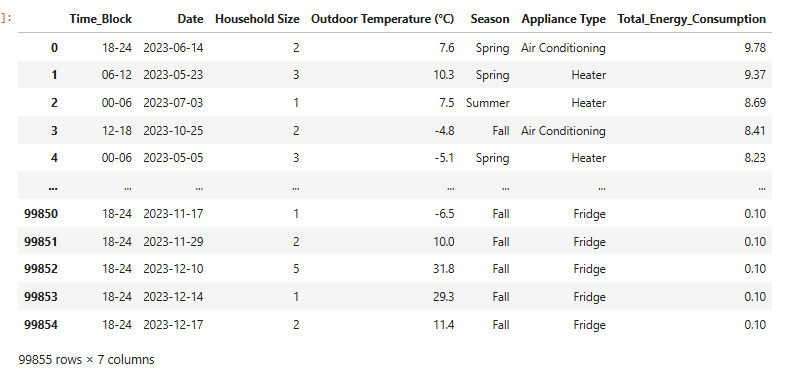
Prepare a data loader
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder,StandardScaler
from sklearn.compose import ColumnTransformer
import numpy as np
# Drop unwanted columns
df = pd_combined_result_dataset.drop(columns=['Unnamed: 0'], errors='ignore')
# Features and target
X = df.drop(columns='Total_Energy_Consumption')
y = df['Total_Energy_Consumption']
# Encode categorical features
categorical_features = ['Time_Block', 'Season', 'Appliance Type']
numeric_features = ['Household Size','Outdoor Temperature (°C)']
target = 'Total_Energy_Consumption'
preprocessor = ColumnTransformer(
transformers=[('cat', OneHotEncoder(handle_unknown='ignore'), categorical_features), # Categorical columns like "Season" = Spring, Summer, Winter"
('num', StandardScaler(), numeric_features)]) # Numeric columns e.g Standard deviation = 1
X = df[categorical_features + numeric_features]
y = df['Total_Energy_Consumption']
X_encoded = preprocessor.fit_transform(X)
# Split into train/test
X_train, X_test, y_train, y_test = train_test_split(
X_encoded, y, test_size=0.2, random_state=42
)
# convert to float32
X_train = X_train.astype(np.float32)
X_test = X_test.astype(np.float32)
y_train = y_train.values.astype(np.float32)
y_test = y_test.values.astype(np.float32)
# checks if X_train and X_test have a method called .toarray(). If they do, it calls that method to convert
# the data into a dense NumPy array. Otherwise, it leaves them as-is.
# TensorFlow/Keras models cannot train directly on sparse matrices — they need dense arrays
X_train_dense = X_train.toarray() if hasattr(X_train, "toarray") else X_train
X_test_dense = X_test.toarray() if hasattr(X_test, "toarray") else X_test
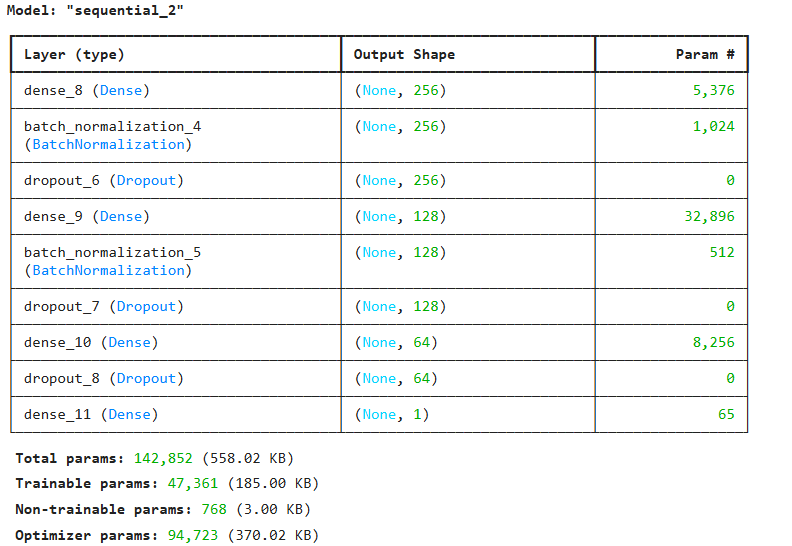
🧠 Construct a Neural Net
layer 1
tf.keras.layers.Dense(256,
activation='relu',
input_shape=(X_train_dense.shape[1],),
kernel_regularizer = tf.keras.regularizers.l2(0.001)),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Dropout(0.4),
- Dense(256): Fully connected layer with 256 neurons.
- Activation: ReLU helps the model learn non-linear patterns.
- input_shape: Specifies the input size based on the training data’s number of features.
- L2 regularization: Adds a penalty to reduce overfitting by discouraging large weights.
- BatchNormalization: Stabilizes and speeds up training by normalizing activations.
- Dropout(0.4): Randomly drops 40% of the neurons during training to prevent overfitting.
layer 2
tf.keras.layers.Dense(128,
activation='relu',
kernel_regularizer = tf.keras.regularizers.l2(0.001)),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Dropout(0.3),
- Dense(128): Fully connected layer with 128 neurons.
- Activation: ReLU helps the model learn non-linear patterns.
- input_shape: Specifies the input size based on the training data’s number of features.
- L2 regularization: Adds a penalty to reduce overfitting by discouraging large weights.
- BatchNormalization: Stabilizes and speeds up training by normalizing activations.
- Dropout(0.3): Randomly drops 30% of the neurons during training to prevent overfitting.
layer 3
tf.keras.layers.Dense(64,
activation='relu',
kernel_regularizer = tf.keras.regularizers.l2(0.001)),
tf.keras.layers.Dropout(0.2),
- Dense(64): Fully connected layer with 64 neurons.
- Activation: ReLU helps the model learn non-linear patterns.
- input_shape: Specifies the input size based on the training data’s number of features.
- L2 regularization: Adds a penalty to reduce overfitting by discouraging large weights.
- Dropout(0.2): Randomly drops 20% of the neurons during training to prevent overfitting.
layer 4
tf.keras.layers.Dense(1)
- Output layer: Liner Regression:
ŷ = wᵀx + b- x = the input vector to the final layer (from the previous layer’s outputs)
- w = weight vector (one weight per input)
- b = bias
- ŷ = predicted value (energy consumption)
import tensorflow as tf
from tensorflow.keras.callbacks import EarlyStopping
# we are constructing 3 layers of nerual nets,
model = tf.keras.Sequential([
tf.keras.Input(shape=(X_train_dense.shape[1],)), # 1D
tf.keras.layers.Dense(256, #Fully connected layer with 256 neurons.
activation='relu', # rulu activation
kernel_regularizer = tf.keras.regularizers.l2(0.001)), #penalty to reduce overfitting by discouraging large weights.
tf.keras.layers.BatchNormalization(), #tabilizes and speeds up training by normalizing activations.
tf.keras.layers.Dropout(0.4), # drop out 40% - Activation: ReLU helps the model learn non-linear patterns. to prevent overfitting
tf.keras.layers.Dense(128,
activation='relu',
kernel_regularizer = tf.keras.regularizers.l2(0.001)),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Dropout(0.3),
tf.keras.layers.Dense(64,
activation='relu',
kernel_regularizer = tf.keras.regularizers.l2(0.001)),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(1) # output layer for regression to caculate the weight and bias and predicted value (how well the traning perfroms)
])
# Helps the model start learning fast and then slow down as it converges.
lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate = 0.01,
decay_steps = 1000,
decay_rate = 0.9
)
# Compile model with learning rate scheduler
optimizer = tf.keras.optimizers.Adam(learning_rate=lr_schedule)
# compile the model
model.compile(
optimizer=optimizer,
loss='mse',
metrics=['mae']
)
# Add early stopping
early_stopping = EarlyStopping(
monitor='val_loss',
patience=15,
restore_best_weights=True
) # keeps the previous learning rate if the current lr is below the defined learning rate for 5 times
# Train the model and track histo~ry
history = model.fit(
X_train_dense,
y_train,validation_split=0.2,
epochs=100,
batch_size=32,
callbacks=[early_stopping],
verbose=1
)
# get test loss value and Mean Absolute Error (average absolute difference between the predicted values and the actual values.)
test_loss, test_mae= model.evaluate(X_test_dense,y_test)
print(f'test MAE: {test_mae}')
1998/1998 ━━━━━━━━━━━━━━━━━━━━ 6s 3ms/step - loss: 0.3680 - mae: 0.4878 - val_loss: 0.3594 - val_mae: 0.4825
Epoch 68/100
1998/1998 ━━━━━━━━━━━━━━━━━━━━ 5s 3ms/step - loss: 0.3693 - mae: 0.4901 - val_loss: 0.3592 - val_mae: 0.4825
625/625 ━━━━━━━━━━━━━━━━━━━━ 1s 1ms/step - loss: 0.3472 - mae: 0.4762
test MAE: 0.4754236340522766
The model stopped at Epoch 68/100 because the model couldn’t learn anything anymore. Let’s check how to model perfroms aganist the test set.
We see the model and traning summary by calling model.summary() to see more details about the training:
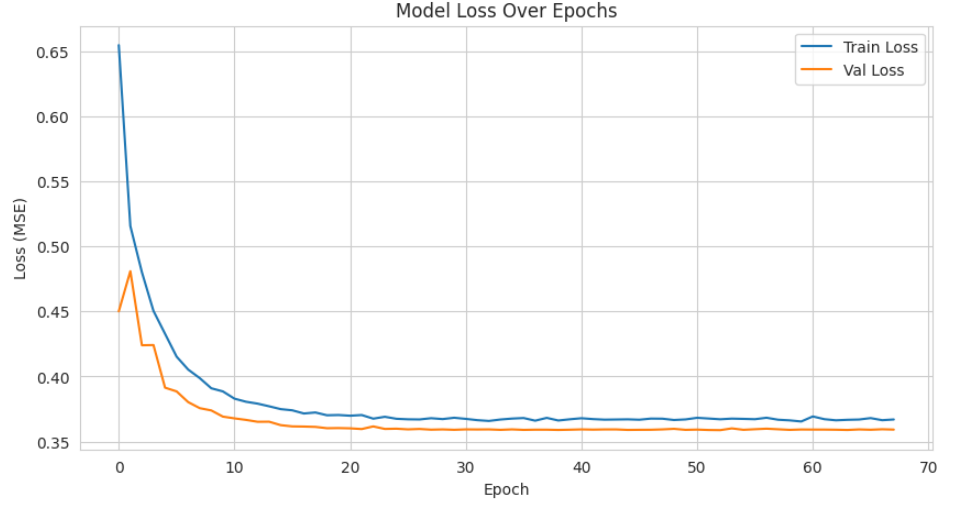
plt.figure(figsize=(10, 5))
plt.plot(history.history['loss'], label='Train Loss') # history trainig step we defined in the model
plt.plot(history.history['val_loss'], label='Val Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss (MSE)')
plt.title('Model Loss Over Epochs')
plt.legend()
plt.grid(True)
plt.show()
if we plot it we can see the tracked traning step we defined in
history = model.fit(
X_train_dense,
y_train,validation_split=0.2,
epochs=100,
batch_size=32,
callbacks=[early_stopping],
verbose=1
)
As shown in the graph below, the model was successfully learning — the loss was decreasing over time due to gradient descent. However, the training stopped at step 68, where it reached a plateau on the validation set, indicating that learning had converged. As a result, the training process was halted early.
Lets check the model prediction against real data and see how it performs:
predictions = model.predict(X_test_dense) # predict the test seet X_test
results_df = pd.DataFrame({
'Actual' : y_test, # compare the orignal dataset y_test
'Predicted' : predictions.flatten() # flatten removes extra dimensions
})
display(results_df)
Looks like it learned from traning data without overfitting too much as we applied drop out to prevent over fitting.
| Actual | Predicted |
|--------|-----------|
| 0.47 | 0.333095 |
| 2.84 | 3.453257 |
| 1.37 | 1.100097 |
| 1.10 | 1.100097 |
| 1.69 | 1.100097 |
📈 Predict energy consumption and costs using real time weather data
import pandas as pd
import requests
# Location (California )
def get_weather_data():
Latitude ="36.7783"
Longitude = "119.4179"
# Dates of interest
top_usage_dates = [
"2025-04-10",
]
weather_data = []
for date in top_usage_dates:
url = f"https://archive-api.open-meteo.com/v1/archive?" \
f"latitude={Latitude}&longitude={Longitude}" \
f"&start_date={date}&end_date={date}" \
f"&hourly=temperature_2m" \
f"&temperature_unit=fahrenheit"
.....
....
# map time blocks of a day
def map_time_block(hour):
if 0 <= hour < 6:
return '00-06'
elif 6 <= hour < 12:
return '06-12'
elif 12 <= hour < 18:
return '12-18'
else:
......
# dataset
avg_temp_data = pd.DataFrame([
{'Time_Block': '00-06', 'Season': 'Spring', 'Appliance Type': 'Fridge', 'Household Size': 3},
{'Time_Block': '06-12', 'Season': 'Spring', 'Appliance Type': 'Air Conditioning', 'Household Size': 3},
{'Time_Block': '12-18', 'Season': 'Spring', 'Appliance Type': 'Microwave', 'Household Size': 3},
{'Time_Block': '18-24', 'Season': 'Spring', 'Appliance Type': 'Heater', 'Household Size': 3}
])
# append the weather data into the dataset
.....
We will use this data for the model to predict
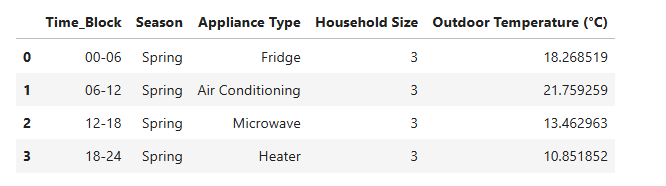
new_data_encoded = preprocessor.transform(avg_temp_data)
x_new_dense = new_data_encoded.toarray() if hasattr(new_data_encoded,'toarray') else new_data_encoded
predicted_consumption = model.predict(x_new_dense).flatten() #converts a multi-dimensional array into a 1D (one-dimensional) array.
avg_temp_data['Predicted Energy comsuption (Kwh)'] = predicted_consumption
avg_temp_data['Estimated Cost ($)'] = predicted_consumption * fixed_rate # Fixed rate 0.166 per kWh calcuated from image understanding
It displyed predicted energy comsuption estimated Cost
📉 Understanding Relationships in Energy Consumption Data
We can observe the relationships between various factors that influence energy consumption. But what if we were dealing with a much larger dataset — with significantly more rows and columns❓
💡 That’s where Generative AI (GenAI) comes in.
We’ll leverage Gemini’s function calling capability to automate these tasks. Function calling allows you to define a function ahead of time and reference it within the prompt. Whenever the user interacts with the model, it automatically triggers the appropriate function — meaning we no longer need to manually write or execute SQL queries each time.
In addition, we’ve pre-trained a model on the dataset to enhance the quality and relevance of the AI’s responses.
def list_tables() -> list[str]:
"""Retrieve the names of all tables in the database."""
# Include print logging statements so you can see when functions are being called.
print(' - DB CALL: list_tables()')
cursor = conn.cursor()
# Fetch the table names.
cursor.execute("SELECT name FROM sqlite_master WHERE type='table';")
tables = cursor.fetchall()
return [t[0] for t in tables]
Output shows we have two table BUT we can discard the grouped_energy_data because we want Gemni to query for us and find the grouped_energy_data for us :
- DB CALL: list_tables()
['grouped_energy_data', 'energy_data', 'hourly_data', 'avg_temp_data']
We describe the table to get an overview
def describe_table(table_name: str) -> list[tuple[str, str]]:
"""Look up the table schema.
Returns:
List of columns, where each entry is a tuple of (column, type).
"""
print(f' - DB CALL: describe_table({table_name})')
cursor = conn.cursor()
cursor.execute(f"PRAGMA table_info({table_name});")
schema = cursor.fetchall()
# [column index, column name, column type, ...]
return [(col[1], col[2]) for col in schema]
- DB CALL: describe_table(grouped_energy_data)
[('Time_Block', 'TEXT'),
('Date', 'TEXT'),
('Household Size', 'INTEGER'),
('Outdoor Temperature (°C)', 'REAL'),
('Season', 'TEXT'),
('Appliance Type', 'TEXT'),
('Total_Energy_Consumption', 'REAL')]
💾 Execute database query generated by Gemini and ask Gemni to query and group dataset
The query that extracts data and group by time blocks and other factors from the dateset:
SELECT
CASE
WHEN CAST(substr(Time, 1, 2) AS INTEGER) BETWEEN 0 AND 5 THEN '00-06'
ELSE '18-24'
END AS Time_Block,
"date",
......
SUM(`Energy Consumption (kWh)`) AS Total_Energy_Consumption
.....
ORDER BY Total_Energy_Consumption DESC
def execute_query(sql: str) -> list[list[str]]:
"""Execute an SQL statement, returning the results."""
print(f' - DB CALL: execute_query({sql})')
cursor = conn.cursor()
cursor.execute(sql)
return cursor.fetchall()
execute_query(sql_query) # execute the query as we did manually above
Make prediction from model
def model_prediction(sql: str) -> list[list[str]]:
"""Execute an SQL statement, returning the results."""
print(f' - DB CALL: model_prediction({sql})')
predict(get_weather_data())
cursor = conn.cursor()
cursor.execute(sql)
return cursor.fetchall()
We can ask Gemini about the dataset while its quering the database under the hood.
db_tools = [list_tables, describe_table, execute_query,model_prediction] # 4 functions to execut
instruction = """You are a helpful chatbot that can interact with an SQL database
for a computer store. You will take the users questions and turn them into SQL
queries using the tools available. Once you have the information you need, you will
answer the user's question using the data returned.
# Use list_tables to see what tables are present, describe_table to understand the
# schema, and execute_query to issue an SQL SELECT query.
"""
# Start a chat with automatic function calling enabled.
chat = client.chats.create(
model="gemini-2.5-pro-exp-03-25",
config=types.GenerateContentConfig(
system_instruction=instruction,
tools=db_tools,
),
)
response = chat.send_message(f"""
I have the following hourly weather-based energy predictions. The model estimates energy consumption and cost based on the outdoor temperature, appliance type, household size, and time of day, using historical data from the grouped_energy_data table.
Please analyze the pattern in this data and provide practical, actionable suggestions to reduce energy consumption and cost. Structure your recommendations in a markdown table, where each row represents a Time Block and each column shows:
- the Time Block
- Most Costly Appliance
- Energy-saving Tips
- Estimated Savings Potential.
Data:
{model_prediction_result}
Your output should include the summary table and a short paragraph explaining the key insights.
data
""")
It provides actionable suggestions to reduce energy costs and on the prediction data :)
💡 Watt-Saver - Your Personalized Energy Coach
This is an AI agent that user can ask questions with their own energy data by training. Below is the LongGraph Implementation with a Chat Agent (Funciton calling + chat):
Prepare LongGraoh nodes: We are using LongGraph’s @tool decorator to execute the functions we define
from collections.abc import Iterable
from random import randint
from langchain.tools import tool
from langchain_core.messages.tool import ToolMessage
# prepre functions for LongGraph to execute and get data to be used for the chat agent.
@tool
def list_tables() -> list[str]:
"""Retrieve the names of all tables in the database."""
.....
return [t[0] for t in tables]
@tool
def describe_table(table_name: str) -> list[tuple[str, str]]:
"""Look up the table schema.
.....
@tool
def execute_query(sql: str) -> list[list[str]]:
.....
return cursor.fetchall()
@tool
def model_prediction(sql: str) -> list[list[str]]:
.....
predict(get_weather_data())
Define the getting weather data function
# Setup the Open-Meteo API client with cache and retry on error
cache_session = requests_cache.CachedSession('.cache', expire_after=3600)
retry_session = retry(cache_session, retries=5, backoff_factor=0.2)
openmeteo = openmeteo_requests.Client(session=retry_session)
class WeatherInput(BaseModel):
latitude: float = Field(description="Latitude for the weather forecast location.")
longitude: float = Field(description="Longitude for the weather forecast location.")
days: Optional[int] = Field(default=3, description="Number of days for the forecast (default is 3). Max 7-10 usually.")
@tool("get_weather_forecast", args_schema=WeatherInput)
def get_weather_forecast(latitude: float = 37.87, longitude: float = -122.27, days: int = 3) -> str:
"""
Retrieves the weather forecast (max/min temperature, max precipitation probability)
for the next few days for a given latitude and longitude.
Defaults to Berkeley, CA if no location is provided. Forecasts for 3 days by default.
"""
if days > 7: # Limit forecast days for simplicity and API limits
days = 7
if days <= 0:
days = 1
url = "https://api.open-meteo.com/v1/forecast"
params = {
"latitude": latitude,
"longitude": longitude,
"daily": ["temperature_2m_max", "temperature_2m_min", "precipitation_probability_max"],
"timezone": "auto",
"forecast_days": days
}
.....
return forecast_string
Define the state for our agent graph
It’s a Python dictionary (TypedDict) that stores:
- The conversation history (messages)
- Any tool outputs (tool_results)
class AgentState(TypedDict):
messages: Annotated[list, add_messages] # Stores the conversation history
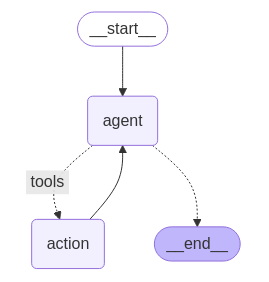
Build graph node and llm then compile
# define Agent components (Nodes and Edges)
# store database memory for agent to fetch
class ToolNodeWithMemory(ToolNode):
def invoke(self, state: dict,config:dict = None) -> dict:
print("--- ToolNode Running ---")
result = super().invoke(state,config=config)
# Store tool results in the state for later use
tool_outputs = result.get("messages", [])[-1].additional_kwargs.get("tool_outputs", [])
if tool_outputs:
# Add to state under a custom key
result["tool_results"] = tool_outputs
return result
# --- LLM Setup ---
# Ensure GOOGLE_API_KEY is available from previous cells
llm = ChatGoogleGenerativeAI(model="gemini-2.0-flash", # gemini-2.5-pro-exp-03-25 can inguest more content becasue has API k
google_api_key=GOOGLE_API_KEY,
convert_system_message_to_human=True) # Important for some agent types
# --- Tool Setup ---
tools = [get_weather_forecast,list_tables, describe_table, execute_query,model_prediction]
tool_node = ToolNodeWithMemory(tools)
# Bind tools to LLM so it knows what functions it can call
llm_with_tools = llm.bind_tools(tools)
# --- Agent Node ---
def agent_node(state: AgentState) -> dict:
"""Invokes the LLM to reason and decide the next action."""
print("--- Agent Node Running ---")
response = llm_with_tools.invoke(state["messages"])
# We return a list, because this will get added to the existing list
return {"messages": [response]}
# --- Graph Definition ---
graph_builder = StateGraph(AgentState)
graph_builder.add_node("agent", agent_node)
graph_builder.add_node("action", tool_node)
graph_builder.add_edge(START, "agent")
# Conditional edge: Does the agent want to call a tool?
graph_builder.add_conditional_edges(
"agent",
# The built-in tools_condition checks the last message
# for tool calls instructions
tools_condition,
# Maps where to go based on the condition
# If tool calls are present, go to "action" to execute them
# Otherwise, finish the graph (END)
{
"tools": "action",
END: END,
},
)
# After executing tools, return control to the agent to process the results
graph_builder.add_edge("action", "agent")
# Compile the graph
graph = graph_builder.compile()
The graph workflow:
🤖 Gemini Chat Agent
## run the agent with energy data and weather request
energy_summary_stats = daily_data.describe().round(2).to_string()
input_prompt = f"""
Using the trimmed_result, identify the specific hours of the day with the highest and lowest energy consumption (kWh).
Return the entire table including all column headers.
Based on the patterns across season, appliance type, outdoor temperature, and household size, provide actionable suggestions to reduce energy costs.
Calculate the energy cost for both the highest and lowest consumption points using a fixed rate of {fixed_rate} USD/kWh.
Decribe the model prediecion on costs and energy consumption regarding the weather factor from
data
{model_prediction_result}
"""
# Define the initial state for the graph
initial_state = {"messages": [HumanMessage(content=input_prompt)]}
# Set recursion limit higher for potential multi-step reasoning
config = {"recursion_limit": 5} # can increase if needs larger data like 10
# inital state
state = graph.invoke(initial_state, config=config)
# The initial response from the AI should be the last message in the state
final_response = state['messages'][-1]
display(Markdown(f"### 🤖 Gemini:\n\n{final_response.content}"))
# loop so we can ask questions unitl we exit so we can have conversations with the dataset we trained with the agent
while True:
user_input = input("🧑 You: ")
if user_input.lower() in ["exit", "quit","q"]:
print('🤖 Gemini: Bye!\n')
break
#add new user message
state["messages"].append(HumanMessage(content=user_input))
# invoke agent with updated state
state = graph.invoke(state, config=config)
response = state['messages'][-1]
display(Markdown(f"### 🤖 Gemini:\n\n{response.content}"))
- Sample questions to ask:
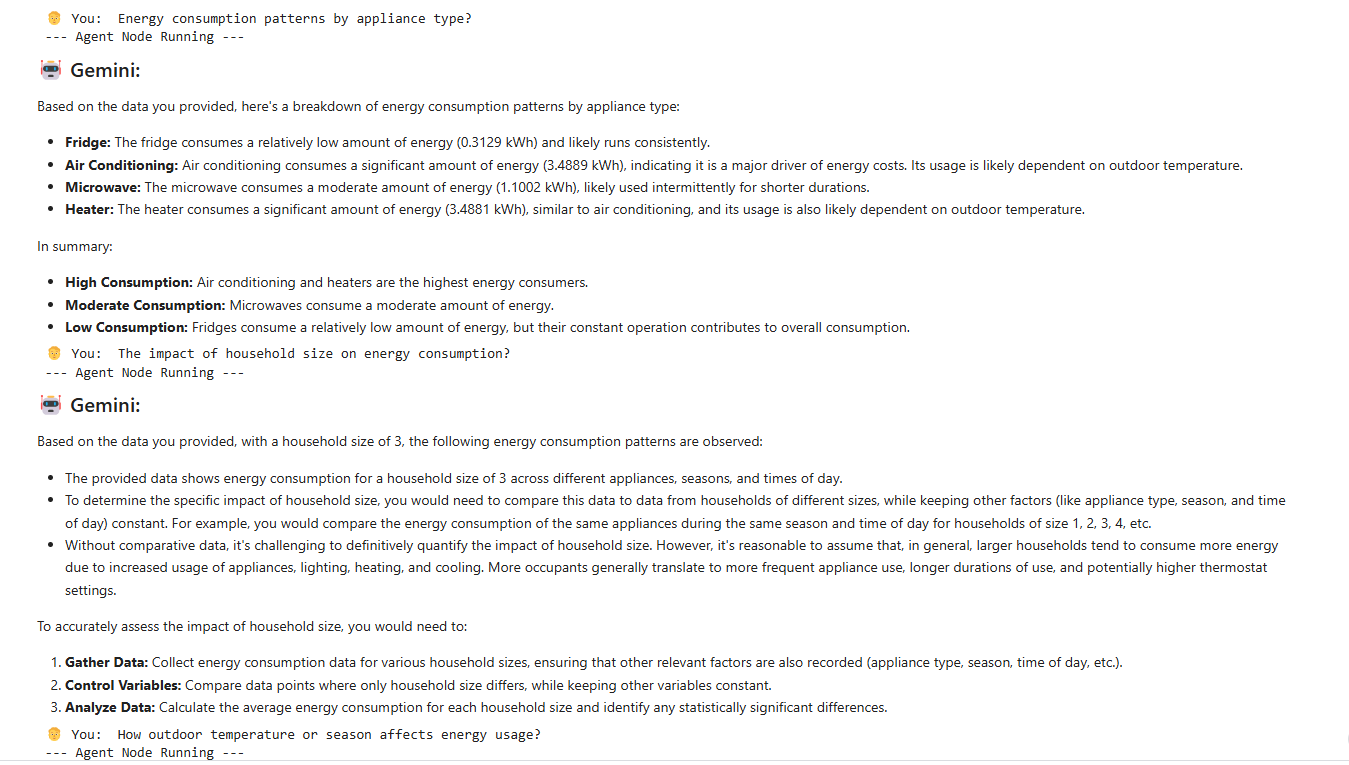
- Energy consumption patterns by appliance type?
- The impact of household size on energy consumption?
- How outdoor temperature or season affects energy usage?
- Specific time blocks with high energy consumption?
- What was the weather prediction on check the
avg_temp_datatable. - What was the weather prediction from the
avg_temp_dataschema and the costs and energy consumption, what the optimiztion you recommand?
🔴 Limitations
1. Limited Access to GPU Resources & Data
Due to limited access to high-performance GPUs and a lack of extensive, personalized datasets, I wasn’t able to train a more advanced or deeply customized model. This constrained the model’s ability to capture highly nuanced energy usage patterns unique to my lifestyle.
2. Time and Experience Constraints
Developing a more robust and accurate model requires deeper domain knowledge and more hands-on experience with advanced modeling techniques. With more time and professional exposure, I believe the model’s performance and personalization could be significantly improved.
3. API Token Limit
The API key you’re using has a token limit, which affects how much data can be passed to the model in a single request. For example, during testing, calling execute_query(sql_query) sometimes exceeded the token limit for gemini-2.5-pro-exp-03-25.
To work around this, I used a trimmed version of the result like trimmed_result = execute_query_reslt[:3000] when working with gemini-2.0-flash, which has a smaller token budget.
If you’re using gemini-2.5-pro-exp-03-25 and want to access a full database table (assuming your token limit allows), you can check out this notebook version — just scroll down to the bottom to view the output. I’ve also included the full output below for convenience:
— Agent Node Running — — ToolNode Running —
- DB CALL: execute_query(SELECT Time_Block, Season, Appliance, Household_Size, Avg_Temperature, Avg_kWh, Avg_Cost FROM grouped_energy_data;) — Agent Node Running — — ToolNode Running —
- DB CALL: list_tables() — Agent Node Running — — ToolNode Running —
- DB CALL: describe_table(grouped_energy_data) — Agent Node Running — 🤖 Gemini: I need more data to answer your question accurately. The provided data only gives overall energy consumption and cost, not a breakdown by appliance type. To determine energy consumption patterns by appliance type (like lighting), you will need to provide a dataset that includes information on individual appliance energy usage. This might involve using smart meters or manually recording energy consumption for each appliance. For example, a dataset might look like this:
| Appliance | Daily Energy Consumption (kWh) |
|---|---|
| Lighting | 1.2 |
| Refrigerator | 2.5 |
| Air Conditioner | 5.0 |
| … | … |
Once you provide such a dataset, I can help you analyze the energy consumption patterns by appliance type.
— Agent Node Running — — ToolNode Running —
- DB CALL: execute_query(SELECT “Appliance Type”, AVG(Total_Energy_Consumption) as Average_kWh FROM grouped_energy_data GROUP BY “Appliance Type”) — Agent Node Running — 🤖 Gemini: Okay, here’s the average energy consumption (kWh) broken down by appliance type, based on the grouped_energy_data table:
| Appliance Type | Average_kWh |
|---|---|
| Air Conditioning | 3.5044 |
| Computer | 1.0968 |
| Dishwasher | 1.1053 |
| Fridge | 0.2987 |
| Heater | 3.4924 |
| Lights | 1.0892 |
| Microwave | 1.1022 |
| Oven | 1.1053 |
| TV | 1.0984 |
| Washing Machine | 1.1027 |
Energy Consumption Patterns by Appliance Type:
Highest Consumption: Air Conditioning and Heaters are by far the most energy-intensive appliances, with average consumption around 3.5 kWh. This aligns with the previous observation that heating and cooling drive peak energy usage. Lowest Consumption: The Fridge has the lowest average consumption (around 0.3 kWh), although it typically runs for longer durations than other appliances. Mid-Range Consumption: Most other appliances, including Lights, Computers, Dishwashers, Microwaves, Ovens, TVs, and Washing Machines, show an average consumption clustered relatively close together, around 1.1 kWh in this dataset.
Regarding “Lighting 1.2”:
The average energy consumption calculated directly from the grouped_energy_data table for “Lights” is 1.0892 kWh. This is quite close to the 1.2 kWh value you mentioned. The difference could be due to rounding in the source data, variations in the specific lighting fixtures included in different groups, or the 1.2 value might represent a specific scenario or a different dataset.
— Agent Node Running — — ToolNode Running —
- DB CALL: execute_query(SELECT “Household Size”, AVG(Total_Energy_Consumption) as Average_kWh FROM grouped_energy_data GROUP BY “Household Size” ORDER BY “Household Size”) — Agent Node Running — 🤖 Gemini: Okay, let’s look at the average energy consumption based on household size from the grouped_energy_data table.
Here’s the data:
| Household Size | Average_kWh |
|---|---|
| 1 | 1.5097 |
| 2 | 1.5152 |
| 3 | 1.4928 |
| 4 | 1.5060 |
| 5 | 1.4872 |
Impact of Household Size on Energy Consumption:
Based on this aggregated data, there doesn’t appear to be a strong, direct correlation between household size and average energy consumption. The average kWh values are remarkably similar across all household sizes (ranging from 1 to 5 people), hovering around 1.5 kWh.
Possible Interpretations:
Averaging Effect: This data represents averages across different times, seasons, and appliance types. It’s possible that while larger households might use more energy overall (e.g., more devices, more frequent use of washing machines/dishwashers), this effect is being averaged out by other factors or potentially offset by different usage patterns (e.g., smaller households might rely more heavily on individual heaters/AC units compared to shared spaces in larger homes). Dominance of Fixed Loads: Certain significant energy consumers (like heating/cooling systems or refrigerators) might have consumption levels that are more influenced by factors like weather, house size/insulation, or appliance efficiency than by the exact number of occupants within this range (1-5 people). Data Granularity: The grouped_energy_data table provides aggregated views. Analyzing more granular data (like the raw energy_data table, if available and appropriate) might reveal more subtle differences or specific scenarios where household size has a clearer impact.
In summary, according to this specific dataset’s averages, household size alone (within the 1-5 person range) does not show a significant impact on the average energy consumption per recorded interval. Other factors like appliance type (especially heating/cooling) and potentially time of day/season seem to be stronger drivers of the variations seen in the data.
— Agent Node Running — — ToolNode Running —
- DB CALL: execute_query(SELECT Season, AVG(“Outdoor Temperature (°C)”) as Avg_Temp_C, AVG(Total_Energy_Consumption) as Average_kWh FROM grouped_energy_data GROUP BY Season ORDER BY Average_kWh DESC) — Agent Node Running — 🤖 Gemini: Okay, let’s examine the relationship between season, average outdoor temperature, and average energy consumption based on the grouped_energy_data table.
Here is the aggregated data:
| Season | Avg_Temp_C | Average_kWh |
|---|---|---|
| Spring | 15.09 | 1.5139 |
| Fall | 14.94 | 1.4998 |
| Winter | 14.86 | 1.4978 |
| Summer | 14.92 | 1.4970 |
Analysis:
Seasonal Consumption: Based on this aggregated data, the average energy consumption is remarkably consistent across all four seasons, hovering around 1.5 kWh. Spring shows a slightly higher average consumption, while Summer shows slightly lower, but the differences are very small. Seasonal Average Temperature: Similarly, the average outdoor temperature calculated for each season in this dataset is extremely close, all around 14.8°C to 15.1°C.
Interpretation: This specific aggregated view (grouped_energy_data) does not show a strong variation in average energy consumption based on season alone, nor does it show significant variation in the average outdoor temperature across seasons. This seems counter-intuitive, as we typically expect higher energy use in Summer (for cooling) and Winter (for heating) due to temperature extremes. The likely explanation is that this table aggregates data in a way that averages out the temperature extremes. While the average seasonal temperature might be around 15°C, there will be much hotter periods within Summer driving AC use and much colder periods within Winter driving Heater use. Our previous analysis (looking at consumption by time block and appliance) clearly showed that Air Conditioning and Heaters are the highest consumers, strongly suggesting that temperature extremes (both hot and cold), rather than the seasonal average temperature shown here, are the key drivers of peak energy usage. In conclusion, while this specific aggregated view shows little difference in average consumption or average temperature across seasons, other analyses of the same underlying data confirm that outdoor temperature extremes significantly impact energy usage due to the activation of heating and cooling systems. The need for these systems varies greatly between and within seasons.
— Agent Node Running — — ToolNode Running —
- DB CALL: describe_table(avg_temp_data) — Agent Node Running — — ToolNode Running —
- DB CALL: execute_query(SELECT * FROM avg_temp_data) — Agent Node Running — 🤖 Gemini: Okay, let’s look at the avg_temp_data table.
Based on the table schema and the data content:
Schema: The table includes columns for Time_Block, Season, Appliance Type, Household Size, Outdoor Temperature (°C), Predicted Energy comsuption (Kwh), and Estimated Cost ($).
Data:
| Time Block | Season | Appliance | Household Size | Outdoor Temp (°C) | Predicted kWh | Estimated Cost ($) |
|---|---|---|---|---|---|---|
| 00–06 | Spring | Fridge | 3 | 18.27 | 0.3104 | 0.5382 |
| 06–12 | Spring | Air Conditioning | 3 | 21.76 | 3.4662 | 6.0104 |
| 12–18 | Spring | Microwave | 3 | 13.46 | 1.1025 | 1.9118 |
| 18–24 | Spring | Heater | 3 | 10.85 | 3.4653 | 6.0089 |
Weather Information in the Table:
The avg_temp_data table doesn’t contain a “weather prediction” in the sense of a future forecast. Instead, it contains average outdoor temperatures (°C) associated with specific time blocks and seasons (in this case, only Spring data is shown).
These temperatures are used alongside other factors (like appliance type) to generate the Predicted Energy comsuption (Kwh) and Estimated Cost ($) shown in the table.
Specifically, the temperatures recorded are:
- 18.27°C for the 00-06 block (associated with Fridge usage)
- 21.76°C for the 06-12 block (associated with Air Conditioning usage)
- 13.46°C for the 12-18 block (associated with Microwave usage)
- 10.85°C for the 18-24 block (associated with Heater usage)
These temperature values directly influence the predicted energy consumption, particularly for temperature-sensitive appliances like the Air Conditioner and Heater.
🤖 Gemini: Bye!
🙏🏻 Thank you
Huge thanks to the incredible moderators and instructors Paige Bailey, Anant Nawalgaria, and the team at Google DeepMind for the opportunity to participate a high-impact, enriching learning & developing experience!
Thanks for reading and every contributor for the project!
📚 Technical approach based on course references:
Build a RAG question-answering system over custom documents
Talk to a database with function calling
Build an agentic ordering system in LangGraph
Tune a Gemini model for a custom task